
빅데이터 분석기사를 준비하면서,
데이터마님의 블로그에 있는
변형 기출문제 및 모의고사를 풀었다.
데이터마님의 블로그에 다른 예제들도 많이 있고
풀이 방법과 문제 풀이 동영상도 있으니
참고해서 공부하면 좋다.
▼아래는 데이터마님의 블로그 링크이다.
DataManim — DataManim
next 1.빅데이터 분석기사 실기 (PYTHON)
www.datamanim.com
위의 블로그에 있는
2회 변경 기출문제를 같이 풀이해보자.
풀이는 코랩으로 진행했다.
작업 1유형

dataURL = https://raw.githubusercontent.com/Datamanim/datarepo/main/krdatacertificate/e2_p1_1.csv

모든 코딩이 그렇지만 위의 문제도 여러가지 방법으로 풀 수 있다.
시험을 칠 때는 한가지 방법만 알아도 문제가 없다.
하지만, 공부할 때는 '다른 방법은 없을까?' 하고 고민해 보는 것이
나중에 더 도움이 되지 않나 하는 생각이 든다.
풀이 방법 1.

① 주어진 데이터셋(df)에서 특정 열(CRIM) 값이 가장 큰 10개의 지역
|
min = df.sort_values(by='CRIM',ascending=False).head(10).CRIM.min()
|
여기서 'sort_values'를 통해 CRIM을 기준으로 데이터를 정렬했다.
'ascending'은 오름차순을 나타내는데,
이 문제에서는 가장 큰 10개의 값이 필요하므로
ascending = 'False'를 넣어 내림차순으로 설정하고(기본값은 오름차순이다.)
가장 위쪽의 10개를 가져왔다. → head(10)
내림차순으로 설정하고 'tail(10)'을 적용하면 동일한 결과를 얻을 수 있다.
|
min = df.sort_values(by='CRIM',ascending=False).head(10).CRIM.min()
|
CRIM 값이 가장 큰 10개 중 최솟값을
'min'이라는 변수로 지정했다.
② 해당 10개 지역의 크림값을 가장 작은 값으로 대체
|
df.loc[df.CRIM >= min,'CRIM'] = min
|
df의 위치(location)를 지정해서 해당 값을 'min'으로 대체했다.
행 : 'CRIM' 값이 min보다 크거나 같다.
열 : 'CRIM' 전체
③ Age 컬럼 값이 80 이상인 대체 된 CRIM의 평균값
| df[df.AGE >= 80].CRIM.mean() |
데이터셋에서 Age 컬럽값이 80 이상인 사람만 남기고
↳ df[df.Age >= 80]
CRIM 열에서 평균을 구했다.
풀이 방법 2.

① 'nlargest'를 사용해서 데이터셋의 CRIM 열에서
상위 10개에 해당하는 부분을 가져왔다.(top10_region)
|
top10_region = df.nlargest(10, 'CRIM')
|
② CRIM값이 가장 큰 것들 중 가장 작은 값을 얻기 위해
위에서 추출한 'top10_region' 에 ' min() '을 적용했다.
|
df.loc[df.CRIM >= min,'CRIM'] = min
|
③ 'df.loc'를 사용해서 df를 대체했다.
|
df.loc[df.CRIM.isin(top10_region.CRIM),'CRIM'] = min_crim
|
행 : top10_region 과 동일
열 : CRIM
④ Age 컬럼 값이 80 이상인 대체 된 CRIM의 평균값은
방법 1과 동일하게 구했다.
참고로, 나는 어떤 데이터셋의 컬럼(열)을 가져올때
편의상 'df.컬럼' 을 사용했는데, 이 방법은 컬럼 이름이
공백이나 특수문자를 포함하지 않는 경우에만 사용 가능하다.
df['컬럼'] ← 왼쪽의 방법으로 사용하는 것이 가장 일반적이며,
모든 상황에서 사용할 수 있는 안전한 방식이다.


① 결측치 대체 전의 표준편차
|
std_before = df.RM.std()
|
std() 를 사용해서 데이터셋의 RM컬럼의 표준편차를 구했다.
② RM의 결측치를 RM의 중앙값으로 대체
|
df.RM = df.RM.fillna(df.RM.median())
|
fillna를 사용하면 결측치를 채울 수 있다.
다만, 그냥 fillna를 사용하면 원본데이터는 수정되지 않기 때문에
대입연산자('df.RM =') 를 사용해서
대체한 결과로 데이터셋을 업데이트 했다.
참고로, 여기서 아래의 코드를 사용하면
| df.RM.fillna(df.RM.median(), inplace=True) |
대입연산자 없이도 원본 데이터프레임인 df가 업데이트된다.
③ 결측치 대치 후의 표준편차
|
std_after = df.RM.std()
|
④ 차이의 절댓값을 소수점 3째자리까지
|
result = round(abs(std_after - std_before),3)
|
①, ③에서 구한 결측치 대치 전후의 표준편차를
빼고 해당값의 절댓값을 소숫점 3째자리까지 표시했다.
이때, 라운드 함수는 2번째 인수에 들어가는 숫자가
소숫점 아래 나타나는 숫자가 된다.

▲ round함수의 2번째 인수에 1 을 넣으면
소숫점 아래 두번째에서 반올림을 해서 소숫점 첫째 자리까지 보인다.
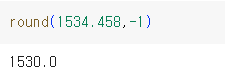
▲ round함수의 2번째 인수에 -1 을 넣으면
1의 자리에서 반올림을 한다.
만약, 0 을 넣으면 소숫점 첫째 자리에서 반올림을 한다.

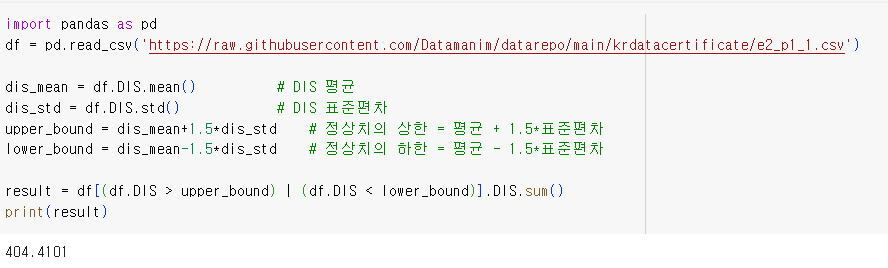
① DIS의 평균, DIS의 표준편차
|
dis_mean = df.DIS.mean() # DIS 평균
dis_std = df.DIS.std() # DIS 표준편차
|
평균, 표준편차를 구하려는 열에 각각
mean(), std() 를 사용한다.
② 이상치와 정상치를 구분하는 영역
|
upper_bound = dis_mean+1.5*dis_std # 정상치의 상한 = 평균 + 1.5*표준편차
lower_bound = dis_mean-1.5*dis_std # 정상치의 하한 = 평균 - 1.5*표준편차
|
이 부분은 특별한 방법은 없다.
문제에 나온대로 구했다.
③ DIS컬럼의 이상치 영역 합을 구한다.
|
result = df[(df.DIS > upper_bound) | (df.DIS < lower_bound)].DIS.sum()
|
df[(df.DIS > upper_bound) | (df.DIS < lower_bound)].DIS
: 위의 부분에서 'OR' 조건을 사용해서 이상치 영역만 추출하고
여기서 다시 DIS 열만 가져온다.
sum()
: sum() 을 사용하면 남은 값의 합을 구한다.

참고로, 여기에서 답을 적을때 'result'라는 변수를 만들고
'print' 함수로 출력했는데,
colab 에서는 특별히 별수를 만들고
프린트를 하지 않아도 결과가 나온다.
다만, 빅분기 시험 환경에서는
반드시 프린트를 해야 하기 때문에
연습할 겸 프린트를 사용하는 것도 나쁘지 않다.
작업 2유형
|
import pandas as pd
# 데이터 로드
x_train = pd.read_csv("https://raw.githubusercontent.com/Datamanim/datarepo/main/shipping/X_train.csv")
y_train = pd.read_csv("https://raw.githubusercontent.com/Datamanim/datarepo/main/shipping/y_train.csv")
x_test= pd.read_csv("https://raw.githubusercontent.com/Datamanim/datarepo/main/shipping/X_test.csv")
#print(x_train.info()) #데이터의 결측치, 데이터 타입 확인
#print(x_train.nunique()) #유일한 데이터의 숫자 확인
# ①-1. 전처리 : 트레인 & 테스트 데이터 구분
x_train_drop = x_train.drop(columns = ['ID'])
x_test_drop = x_test.drop(columns = ['ID']) #트레인 데이터를 수정 할 때 테스트 데이터도 동시에 수정해야 함!!
y_train = y_train.drop(columns = ['ID'])
cust_id = x_test.ID # 결과 출력에 사용될 고객 아이디
# ①-2 . 전처리 :인코딩(원핫 인코딩 or 라벨 인코딩)
#원핫 인코딩
x_train_dum = pd.get_dummies(x_train_drop)
x_test_dum = pd.get_dummies(x_test_drop).reindex(columns = x_train_dum.columns, fill_value = 0) #x_train_dum과 x_test_dum의 컬럼값을 동일하게 함
# ② 학습 : 알고리즘 선택(랜덤포레스트 분류)
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score
# ③-1. 학습 : 트레인 데이터를 실제로 학습시킬 데이터와 검증할 데이터로 분류
X_train, X_validation, Y_train, Y_validation = train_test_split(x_train_dum, y_train, test_size = 0.2, random_state = 2)
# ③-2. 검증 및 결과 : 랜덤포레스트 모델 사용
model = RandomForestClassifier()
model.fit(X_train, Y_train)
print('score : ', f1_score(Y_validation, model.predict(X_validation))) #검증 데이터 확인
pred = model.predict(x_test_dum) #결과 예측
# 답안 제출
pd.DataFrame({'ID':cust_id, 'pred': pred}).to_csv('reult.csv', index=False)
|
2유형 풀이는 위와 같다.
어떻게 했는지 하나씩 알아보자.
0. 데이터 확인
|
print(x_train.info()) #데이터의 결측치, 데이터 타입 확인
|
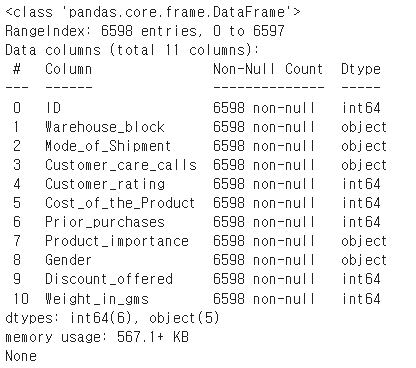
먼저 어떤 데이터인지 확인 할 필요가 있다.
info() 를 사용해서 어떤 컬럼이 있는지,
결측치는 있는지,
데이터 타입은 무엇인지 확인 할 수 있다.
만약 날짜가 필요한데 데이터 타입은 그렇지 않을 수도 있고,
혹은 숫자가 필요한데 데이터 타입은 문자일 수도 있다.
결측치가 있는 경우 결측치가 있는 부분을 삭제하거나,
혹은 특정 데이터를 채워줄 수 있다.
또 데이터 타입이 원하는 형태와 맞지 않는다면
바꾸어주어야 한다.
이번 문제에서는 결측치도 없고
데이터 타입을 바꾸어야 할 컬럼도 없다.
| print(x_train.nunique()) #유일한 데이터의 숫자 확인 |

nunique() 를 사용해서 해당 컬럼에 유일한 값이 몇개인지
확인 할 수 있다.
예를 들어서, Gender에는 남자와 여자를 나타내는
두가지 값이 있기 때문에 '2'가 된다.
①-1. 전처리 : 트레인 & 테스트 데이터 구분
|
x_train_drop = x_train.drop(columns = ['ID'])
x_test_drop = x_test.drop(columns = ['ID'])
y_train = y_train.drop(columns = ['ID'])
|
트레인 데이터, 테스트 데이터를 수정할 때는
항상 같이 해 주어야 한다.
(x_train_drop, x_test_drop)
두 개의 변화가 일치하지 않는다면,
절적한 예측결과를 얻기 어렵다.
학습 데이터에 'ID' 컬럼은 필요하지 않다.
어차피 'ID'는 모두 다르며,
여기에서 특별한 공통점을 찾기는 쉽지 않다.
|
cust_id = x_test.ID # 결과 출력에 사용될 고객 아이디
|
학습데이터에는 'ID'가 필요하지 않지만,
결과를 출력할 때는 필요하기 때문에
테스트 데이터의 'ID'를 따로 변수로 만들었다.
①-2. 전처리 : 인코딩(원핫 인코딩)
|
x_train_dum = pd.get_dummies(x_train_drop)
x_test_dum = pd.get_dummies(x_test_drop).reindex(columns = x_train_dum.columns, fill_value = 0)
|
위에서와 마찬가지로,
트레인 데이터와 테스트 데이터 모두를 수정했다.
'pd.get_dummies(x)'를 하면 'x'데이터를 원핫 인코딩 할 수 있다.
인코딩은 범추형 데이터를 수치형 데이터로 변환하는 과정인데
이를 통해서 내가 설택한 학습 모델이
데이터를 더 잘 이해하고 처리할 수 있게 된다.
라벨 인코딩, 원핫 인코딩, 빈도 인코딩, 순서 인코딩 등
다양한 인코딩이 있는데,
이에 대한 자세한 내용은 따로 다루겠다.
(그냥 원핫 인코딩만 알아가도 문제는 없다.)
(괜히 어설프게 전처리를 해 버리면 안하느니만 못하다.)
| reindex(columns = x_train_dum.columns, fill_value = 0) |
x_test 데이터를 원핫 인코딩 할때,
x_text_dum 의 컬럼을 x_train_dum 의 컬럼과 동일하게 만들어 준다.
x_train_dum 에 있는 'A'라는 컬럼이
x_test_dum 에는 없는 경우
'A'라는 컬럼을 x_test_dum 에 추가하고 그 값은 '0'으로 채운다.
| x_test_dum = pd.get_dummies(x_test_drop)[x_train_dum.columns] |
▲참고로, 위의 방법으로 컬럼을 맞춰주는 방법도 있긴 한데
이 경우에는 테스트 데이터(x_test_dum)의 컬럼에
x_train_dum 에 있는 컬럼만 남긴다.
즉, x_test_dum에 어떤 컬럼이 더 추가되지는 않고
없어지기만 한다.
결과적으로, reindex를 사용한 방법이 일치하는 컬럼이 더 많고
따라서, 에러가 발생할 확률이 더 낮다.
추가로, 전처리에는 이상치 처리, 정규화, 정규분포 변환,
이산형화, PCA등이 있는데
앞서 말했듯이 빅분기의 문제에서는
굳이 하지 않아도 된다.
②. 학습 : 알고리즘 선택
|
from sklearn.ensemble import RandomForestClassifier
|
알고리즘의 종류는 다양하고
또 알고리즘 안에서도 파라미터 튜닝 등
예측 결과를 더 좋게 하는 방법은 다양하다.
다만, 랜덤포레스트만 사용해도
점수를 얻을 수 있을 만한 결과는 얻을 수 있으므로
랜덤포레스트만 사용해도 무방하다.
(가장 쉽다.)
|
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score
|
알고리즘을 선택하는 김에
데이터를 나누어주는 train_test_split,
앞서 문제에서 평가지표로 언급했던 f1_score 를
같이 불러왔다.
③-1. 학습 : 데이터 분류(학습, 검증)
|
X_train, X_validation, Y_train, Y_validation = train_test_split(x_train_dum, y_train, test_size = 0.2, random_state = 2)
|
학습 데이터를 검증해 보기 위해서
학습 데이터 안의 데이터 일부를 검증 데이터로 떼어냈다.
참고로, '굳이 검증을 하지 않아도 될거 같다' 하면
검증 데이터를 따로 구분할 필요는 없다.
단지, 결과가 어느정도 나오나 확인을 하기 위함이며,
점수에는 영향을 끼치지 않을 가능성이 높다.
물론, 확인해 볼 수 있다는 점에서 마음의 위안을 얻을 수는 있다.
random_state = 2
random_state 는 아무 숫자나 넣어주어도 무방하다.
특정 숫자를 설정함으로서 반복된 수행에서
동일한 결과를 얻을 수 있다.
좀 더 구체적으로, 숫자를 넣어주면
데이터를 분할할 때 훈련데이터와 검증데이터를 동일하게 분할하여
모델의 학습결과를 일관성 있게,
재현성이 높게 만들 수 있다.
random_state 를 생략하면 프로그램을 디버깅할때마다
결과값이 달라진다.
③-2. 학습 : 검증 및 결과 예측
|
model = RandomForestClassifier()
model.fit(X_train, Y_train)
print('score : ', f1_score(Y_validation, model.predict(X_validation))) #검증 데이터 확인
pred = model.predict(x_test_dum) #결과 예측
|
이번 문제는 정시 도착여부
즉, 1 또는 0 (이산적인 타겟)을
판단해야 하기 때문에 분류문제이고 따라서,
RandomForestClassifier() 를 사용했다.
이 모델 이름을 계속해서 적기에는 길기 때문에
model 이라는 변수로 대체했다.
fit 을 통해서 주어진 데이터를 학습하고,
predict 를 사용해서 예측을 수행할 수 있다.
| print('score : ', f1_score(Y_validation, model.predict(X_validation))) #검증 데이터 확인 |
여기서 검증 데이터들로 그 결과값이 얼마나
맞는지 확인 할 수 있다.
참고로, 만약 연속적인 값을 예측해야 한다면
회귀(Regressor)문제이며 이 경우
RandomForestRegressor() 를 사용 할 수 있다.
④ 답안 제출
|
pd.DataFrame({'ID':cust_id, 'pred': pred}).to_csv('reult.csv', index=False)
|
답안 제출은 특별하지 않다.
문제에서 제시한 방식대로
데이터프레임을 생성해서 csv 파일을 만들어준다.
유형 2번의 경우 어느 정도 루틴이 있기 때문에
해당 루틴만 잘 외워가도 좋은 점수를 받을 수 있다.
유형 2번에 대해서는 따로 좀 더 상세히
설명하겠다.
작업 3유형


▲ 주어진 데이터는 위와 같다.

문제를 해결하기에 앞서서,
이 데이터의 height 컬럼은 데이터 타입이 'object'이다.
즉, 숫자는 아니라는 것이며
따라서, 바로 평균을 구할 수는 없다.
① 해당 데이터에서 'cm'를 제거하고
② 데이터 타입을 실수로 바꿔주어야 한다.
| df['height_float']=df['height'].str.replace('cm','').astype('float') - 방법 1 df['height_float2'] = pd.to_numeric(df['height'].str.replace('cm','')) - 방법 2 df['height_float3'] = df['height'].apply(lambda x : float(x.replace('cm',''))) - 방법 3 |
▲ 해당 코딩은 위의 방법중 하나로 할 수 있다.
(이렇게 할 수도 있다를 알려주기 위해 여러가지 방법을 썼다.)
위의 코딩을 실행하면,
▼ 아래와 같은 결과를 얻을 수 있다.
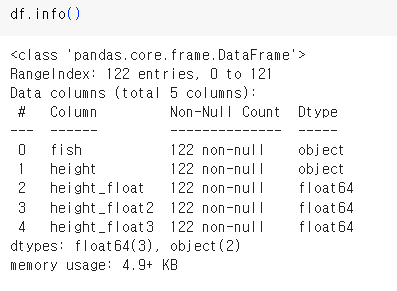
▲ height_float1,2,3 의 Dtype이 float64인 것을 볼 수 있다.

▲ height_float1,2,3 의 값은 모두 동일하다.

새로 만든 컬럼에 mean() 을 적용하고
소숫점 5째 자리까지 나오게 반올림(round)해서
결과를 출력했다.

여기서 보면, 문제가 일표본 t검정이다.
표본이 1개 있는 t검정을 하라는 것이며,
이는 ttest_1samp() 을 사용해서 할 수 있다.
ttest_1samp() 함수를 사용하면
검정통계량(s), p-value(p) 를 구할 수 있다.

▲검정통계량(s)을 소숫점 셋째자리까지 출력했다.

p-value는 0~1 사이의 값으로 표현되는데
유의수준과 비교해서
p-value가 유의수준보다 작으면(p<유의수준)
귀무가설을 기각하고(=대립가설)
p-value가 유의수준보다 크거나 같으면(p>=유의수준)
귀무가설을 기각할 수 없다.(=귀무가설 채택)
참고로 '귀무가설 기각'이라고 하면,
통계적으로 유의한 차이가 있다고 판단할 수 있다.
반대로, '귀무가설 채택'의 경우
통계적으로 유의한 차이가 없다고 판단할 수 있다.

결과적으로, p-value를 소숫점 셋째자리까지 구하면,
0.829 이며 이는 0.05보다 크므로
'귀무'라고 할 수 있다.

마지막 문제는 확률문제이다.

▲ 이항분포(독립적 시행을 일정 횟수 방법)와 관련된
확률 계산은 binom(Binomial Distribution) 함수를
사용할 수 있다.

3-2-a 에서는 21명 중 16명 미만이 치과를 찾았을 확률이므로,
1~15명이 치과를 찾았을 확률을 모두 더해주면 된다.

즉, n번의 시행까지의 누적된 확률을 구하면 된다.
이는 binom.cdf 함수를 사용할 수 있다.

적어도 19명이 치과를 찾았을 확률은,
19명 또는 20명이 치과를 찾았을 경우의 확률을 뜻한다.
이 경우 아래의 두가지 방법을 사용할 수 있다.
방법 ①. 19명 확률 + 20명 확률 : binom.pmf()
방법 ②. 전체 확률 - 1~18명까지의 확률 : 1-binom.cdf()

▲ pmf(Probability Mass Function) 는 확률질량함수로
각각의 시행에 대한 확률을 구하는 함수이다.
여기까지,, 길었던 데이터마님 블로그의 2회기출변형을 마친다.
유형1은 많이 풀어보는게 답이고,
유형2는 루틴만 잘 외워야 되고
유형3은 어느정도 공부를 해야 될 수 있다.
유형 2,3에 대해서는 다른 포스팅에서 따로 다루어 보겠다.
'자격증 이모저모 > 빅데이터 분석기사(파이썬)' 카테고리의 다른 글
| 빅데이터 분석기사 실기 2유형 빠르게 정복하기 (1) | 2023.07.10 |
|---|---|
| 빅데이터 분석기사 실기 3번만의 합격(제 6회) 후기 및 꿀팁 (0) | 2023.07.08 |
| 빅데이터 분석 필답 대비 1 (1) | 2023.04.12 |

