
작업 2유형에서
어설픈 전처리나 최적화는
오히려 결과를 나쁘게 만들 수 있고
따라서 자신이 없다면
최소한의 코딩으로 끝내는 것을 추천한다.
잘못된 전처리의 결과에 대한 내용은
▼아래의 후기에 적어두었다.
빅데이터 분석기사 실기 3번만의 합격(제 6회) 후기 및 꿀팁
그리고 이 최소한의 코딩은
어느 정도 정형화 시킬수 있다.
즉, 문제를 쉽게 풀 수 있다.
물론, 여러가지를 공부해서
문제에 맞춰서 전처리를 이것저것 해 주면
더 좋겠지만
단지 시험통과가 목표라면
아래의 내용만으로도 충분하다.
다시말해서, 지금부터
오직, 시험 점수를 위한 작업2유형 풀이를 알아볼 것이다.
좀 더 다양한 방법을 알고 싶다면,
책을 보는 것을 추천한다..
목차
1. 데이터 확인 : 데이터 타입, 결측치, 고유값
2. 전처리 : 결측치 제거 & 인코딩 & 트레인▪테스트 데이터 구분
3. 알고리즘 선택 : 랜덤 포레스트
4. 학습 & 예측
- 트레인 데이터의 일부를 검증용 데이터로 구분 및 예측결과 비교
5. 전체 복습
1. 데이터 확인 : 데이터 타입, 결측치, 고유값
▲데이터 안에 어떤 컬럼이 있고,
그 컬럼의 값은 어떤 것인지는 당연히 확인해야 한다.
참고로 시험에서는 csv 파일이 들어가 있고,
그래서 해당 데이터를 그냥 볼 수 있다.
이건 진짜 그냥 보면 아,, 이런 뜻이구나,,
라는걸 알 수 있다.
참고로, 위의 데이터는 데이터마님 블로그의
기출5회 변형에서 가져왔다.
링크를 걸어두었으니, 궁금하신 분들은
가서 확인하면 되겠다.
▲print() 함수를 사용한 결과이다.
여기서 9823개의 행(rows)과
10개의 열(columns)을 가진것을 볼 수 있다.
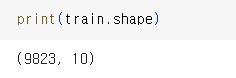
▲데이터를 꼭 print() 로 봐야 할 필요는 없기 때문에
shape 를 써서 행, 열이 각각 몇 개인지만
확인할 수도 있다.

데이터 타입이 어떤지는
굳이 확인하지 않아도 된다.
(물론, 어떻게 하냐에 따라 다르겠지만
원핫인코딩을 하면 데이터 타입은 무시될 수 있다.
확인해서 나쁜건 아니다. 필요의 문제랄까..)

다만, 결측치와 유니크한 값이 몇개인지는
확인하는 것을 추천하는데,,
여기는,,, 결측치가 없다.

유니크한 값이 몇개인지 봤을 때,
price 는 우리가 예측해야 할 값이니 넘어가고,
mileage 가 7,550개나 되는 것을 볼 수 있다.
이 정도면 날려도 되지 않나,, 싶은데,,
뒤쪽에서 보도록 하자.
(뭐 아무것도 안하는게 베스트일수도 있다.)
2. 전처리
② 결측치 제거
결측치가 없는 경우 아무런 문제가 없지만,
결측치가 있다면
데이터 특성에 따라 뒤쪽에서
에러가 생기는 경우가 있다.
따라서, 결측치를 처리하는 것을 추천한다.
(결측치(missing values)에 관련된 에러가 뜨면
그때 처리해도 된다.)

특정 열에 결측치가 너무 많은 경우,
해당 열을 통째로 날릴 수도 있다.
↳ dropna(axis = 1)
결측치가 몇 되지 않는 경우,
해당하는 행만 날릴 수도 있다.
↳ dropna()
0, 중간값, 평균값 등 원하는 값으로
채워줄 수도 있다.
↳ fillna(0), fillna(train.column.mean()), ···
③ 트레인, 테스트 데이터 구분

조금 늦은거 같지만, 문제를 설명하면
우리는 어떤 중고 차량들의 정보(x_train)와
그 정보에 따른 가격을 학습(y_train)한다.
학습 결과와 다른 어떤 중고차량의 정보(x_test)를 토대로
중고차의 가격을 예측(predict)한다.
ID 는 그냥 각각을 구분하는 번호이기 때문에
가격에 영향을 전혀 주지 않는다.
따라서, 배제했다.

참고로, 나는 'mileage'의 유무에 따른 결과 차이를 보기 위해서
x_train1, x_train2 로 데이터를 나누었다.
④ 인코딩
원핫 인코딩을 해 준다.
원핫 인코딩은 범주형 데이터를
숫자로 표현하는 방법 중 하나인데,
간단하게, 원핫인코딩을 사용하면
학습을 더 잘할 수 있다.

▲ 원핫 인코딩은 pd.get_dummies() 를 사용한다.
이때, test 데이터는 reindex() 함수를 적용해서
train 데이터와 컬럼 값을 맞춰주어야 한다.
(맞추지 않으면 에러가 발생할 수 있다.)

참고로, 위의 방법으로 라벨 인코딩을 할 수도 있다.
음,, 자세한 내용은 따로 포스팅 하도록 하겠지만,
라벨링 인코딩은 범주형 변수의 각 카테고리를
정수로 매핑하고,
(ex. 고양이 → 0, 개 → 1, 토끼 → 2)
원핫 인코딩은 범주형 변수의 각 카테고리를
이진형태로 매핑한다.
(ex. 고양이 → [1 0 0], 개 → [0 1 0], 토끼 → [0 0 1])
또, 라벨 인코딩은 순서나 크기에 따라
가중치를 부여할 수도 있긴 한데,,,
(그래서 순서나 크기에 의미가 있는 경우 라벨 인코딩이 좋다.)
빅분기에서 가중치를 부여할만한 문제는,,,
나는 아직 보지 못했다,,,
3. 알고리즘 선택 : 랜덤 포레스트

이번 문제는 가격을 예측 하는 문제이다.
즉, 연속적인 값을 예측하는 문제이며,
이러한 문제를 회귀(Regressor)문제라고 한다.
가격 외에도 온도 예측, 부피 예측 등이 될 수 있다.
참고로, RandomForestClassifier 는
분류(Classifier) 문제에 사용한다.
분류는 이산적인 타겟을 예측 할 때 사용한다.
(ex . 0 또는 1인지를 예측)
문제에서 평가지표를 알려준다.
평가지표에는 f1_score, precision_score,
mean_squared_error 등이 있는데,
5회 실기시험에서는 rmse 값을 통해 검증하라고 했다.
mse(mean_squared_error)는 함수를 사용하면 되고,
root(제곱근)는 NumPy 라이브러리로 구할 수 있다.
5회차 필기 시험을 칠 당시 그걸 몰라서
그냥 mse로 검증했고,, 오,,?
이상하네 괜찮은거 같네,,? 하고 나왔다,,
(애초에 구분으로 문제를 풀어서 틀렸다.)

sklearn 라이브러리를 사용하면
데이터를 나누고 나뉘어진 데이터로
검증해 볼 수 있다.
test 데이터에는 'price'값이 없으므로
실제 결과가 얼마나 정확한지 확인 할 수 없고
그래서 따로 검증 데이터를 통해
어느정도 되나 가늠해 볼 순 있다.
검증결과가 너무 좋지 않으면,,
random_state 부분을 지우고
반복해서 돌려보면 결과가 잘 나올 수도 있다,,,
혹은, 쓸모 없어 보이는 열을 지운다던가,,,
(사실,, 마음만 아프지 않나,, 하는 생각이,,)
검증을 위해서 테스트(학습) 데이터를
실제로 학습시킬 데이터와 검증할 데이터로
분류한다.
이때, test_size = 0.2 로 하면
검증 데이터의 크기가 전체 데이터의 20 %가 된다.
random_state 는 아무 숫자나 넣어주는데,
특정 숫자를 설정하면
데이터를 분할할 때 훈련데이터와 검증데이터를
동일하게 분할하여
반복적인 수행에서도
결과를 일관성있게 만들어준다.
4. 학습 & 예측
① 검증
- 트레인 데이터의 일부를 검증용 데이터로 구분 및 예측결과 비교
이 부분은 꼭 필요하진 않은데,,
쨋든, 'mileage' 컬럼을 그대로 두었을 경우(score1)와
해당 컬럼을 삭제했을 경우(score2)의 rmse 값을 비교해 보았다.

오,,, 역시나,,,
아무것도 하지 않는게,,,
rmse는 실제 예측값과 관측값의 차이를 나타내는
오차 제곱 평균의 제곱근이다.
즉, 작을수록 예측값과 관측값이 유사한 것이며,,
결과에서 보면 그냥 그대로 하는 것이 결과가 좋다.
다시 한번 말하지만,
기본만 하는게,,,
② 학습

다시 기본으로 돌아오면,
RandomForestRegressor() 라는 학습모델이름을
모두 적어주면 너무 길기 때문에
간결하게 작성하기 위해
model 이라는 변수로 대체하고
model.fit 등으로 사용하는데
그냥 RandomForesstRegressor().fit(X_train,Y_train) 이렇게
적어도 문제는 없다.
fit(X,Y) 를 사용하면 데이터를 학습시킬 수 있다.
이 때, 검증을 하지 않으려면
데이터를 나눌 필요도 없고
따라서, 위의 코딩 대로라면
x_train_dum 과 y_train 을 학습시키면 된다.
↳ model.fit(x_train_dum, y_train)
③ 예측 및 답안 제출

결과 예측 및 답안 제출이다.
학습시킬때 원핫인코딩 시킨 데이터를 학습시켰으므로
예측에도 반드시 원핫인코딩 시킨 데이터를 사용해야 한다.
예측은 model.predict()를 사용할 수 있으며,
문제에 따라 다를 수 있는데,
평가지표가 roc_auc_score 또는 확률이라면
결과예측에서 model.predict_proba(x_test)[:1]
을 사용해야 한다.
↳ model.predict_proba(x_test_dum)[:1]
답안 제출은 시키는 대로 하면 되는데,
보통 시험문제에서 친절하게 알려준다.
5. 전체 복습
'1. 데이터 확인' 단계에서는
어떤 데이터인지 확인하고,
'2. 전처리' 단계에서는 데이터를 적절하게 가공한다.
결측치 제거, 원핫 인코딩,
학습/테스트 데이터 구분 등을 할 수 있다.
'3. 알고리즘 선택' 단계에서 알고리즘을 선택하는데,
그냥 RandomForestClassifier/Regressor 을 쓰면 된다.
참고로 xgboost가 조금 더 괜찮은 결과를 낼 수 있는데,
조금 무거워져서 시험 pc에서 돌아가지 않을 수도 있다.
↳ from xgboost impot XGBclassifier / XGBRegressor
'4. 학습 & 예측' 단계에서
원한다면 검증용 데이터를 만들어서
예측 결과가 어느정도 나오는지 확인 해 볼 수 있다.
만들어준 데이터를 학습시키고
테스트데이터로 예측을 진행한다.
전체 코딩은 아래와 같다.
|
import pandas as pd
# 데이터 로드
x_train = pd.read_csv("https://raw.githubusercontent.com/Datamanim/datarepo/main/shipping/X_train.csv")
y_train = pd.read_csv("https://raw.githubusercontent.com/Datamanim/datarepo/main/shipping/y_train.csv")
x_test= pd.read_csv("https://raw.githubusercontent.com/Datamanim/datarepo/main/shipping/X_test.csv")
# 데이터 정보 확인
# print(x_train.info()) # 데이터 타입이 어떤지
# print(x_train.isnull().sum()) # 비어 있는 값(null)이 몇개나 되는지 → 비어있는 경우 채워주는게 좋음
# #결측치가 특정 컬럼(열)에 많으면 해당 컬럼은 날리는게 좋을 수도 있음
# print(x_train.nunique()) # 범주형 변수인데 유일한 변수가(unique) 많으면 해당 컬럼은 날려도 됨
#결측치 대체
# train = train.fillna(0) # 결측치 '0'으로 채움
# train = train.fillna(method ='ffill') # 결측치를 이전 값으로 채움
# # 평균, 중간값 등으로 결측치 채울 수 있음
# 결측치가 많지 않다면, 해당 결측치가 있는 행 자체를 삭제해도 무방
# train = train.dropna(axis = 1) # 결측치가 있는 열 전체 삭제
# 특정 열에 결측치가 너무 많다면, 해당 열 전체를 삭제하는 것이 나을수도 있음
# train = train.dropna() # 결측치가 있는 행 전체 삭제
# 예측 모델을 사용해서 결측치 값을 예측할 수도 있음(그냥 그럴 수도 있다..)
#트레인 & 테스트 데이터 구분
x_train = train.drop(columns = ['ID','price'])
y_train = train['price']
x_test = test.drop(columns = ['ID']) #트레인 데이터를 수정 할 때 테스트 데이터도 동시에 수정해야 함!!
cust_id = test.ID # 결과 출력에 사용될 고객 아이디
# 인코딩 : 원핫 인코딩
#원핫 인코딩
x_train_dum = pd.get_dummies(x_train)
x_test_dum = pd.get_dummies(x_test).reindex(columns = x_train_dum.columns, fill_value = 0)
# 알고리즘 : 랜덤포레스트 모델
# from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import RandomForestRegressor
#검증 모델
from sklearn.metrics import mean_squared_error #f1_score, accuracy_score, recall_score, roc_auc_score, precision_score
import numpy as np #root 를 하기 위함
# 트레인 데이터를 실제로 학습시킬 데이터와 검증할 데이터로 분류
from sklearn.model_selection import train_test_split
X_train, X_validation, Y_train, Y_validation = train_test_split(x_train_dum, y_train, test_size = 0.2, random_state = 42)
X_train2, X_validation2, Y_train2, Y_validation2 = train_test_split(x_train_dum2, y_train, test_size = 0.2, random_state = 42)
#학습 및 결과 예측
model = RandomForestRegressor()
model.fit(X_train, Y_train)
# pred_validation = model.predict(X_validation)
# print('score : ', np.sqrt(mean_squared_error(Y_validation,pred_validation))) #검증 데이터 확인
#결과 예측
pred = model.predict(x_test_dum)
#pred = mode.predict.proba(x_test_dum)[:1]
# 답안 제출
pd.DataFrame({'ID':cust_id,'pred': pred}).to_csv('reult.csv', index=False)
|
나는 빅데이터분석기사 실기시험을
3번(4,5,6회차 응시) 만에 합격했다.
2유형은 4회차 시험에서 20점,
5회사 시험에서 0점,
6회차 시험에서 40점을 받았다.
공부를 충분히 하지 않았기 때문에
여러번 떨어졌지만,
덕분에 여러 번의 경험을 했고
'이렇게만 해도 점수가 나오는구나.'
라는 것을 알게 되었다.
물론, 시험 문제마다 다르고
그래서 만족할 만한 결과를 얻지 못할 가능성도 존재하겠지만,
내 경험상 이 정도면 부족하지는 않을 것이라고 확신한다.
참고하면 좋은 내용.
'자격증 이모저모 > 빅데이터 분석기사(파이썬)' 카테고리의 다른 글
| 빅데이터 분석기사 실기 3번만의 합격(제 6회) 후기 및 꿀팁 (0) | 2023.07.08 |
|---|---|
| 빅데이터 분석기사 실기 2회 변형 기출문제 풀이(feat. 데이터마님) (2) | 2023.07.07 |
| 빅데이터 분석 필답 대비 1 (1) | 2023.04.12 |

